Listen to this article:
The Rise of Specialized Models
The future of AI isn't just about deploying massive frontier models; it's also about creating specialized models tailored to specific tasks and datasets. As NVIDIA highlighted in recent research, small specialized models are becoming the foundation of multi-agents AI systems, where multiple purpose-built models work together rather than relying on a single general-purpose giant.
But here's the challenge: Fine-tuning or training these specialized models, even when they're small by modern standards, requires serious infrastructure. A multi-billion parameter model demands distributed training across multiple GPUs, often spanning multiple nodes to provide it with large datasets. For organizations looking to build custom models on proprietary data, the infrastructure layer becomes the bottleneck, not the ML expertise.
The traditional approach of provisioning static GPU clusters doesn't work well for this use case. Training runs are intermittent, GPU requirements vary by experiment and the cost of idle hardware quickly becomes prohibitive. What we need is infrastructure that scales dynamically, provisions the exact hardware required for each training run and gets out of the way when the work is done.
In this blog post, we’ll walk through how to build such an environment and implement it in practice.
A Kubernetes-Native Solution for Dynamic GPU Training
The solution centers on three key technologies working together: Kubernetes for orchestration, Karpenter for automatic node provisioning and Kubeflow for distributed training jobs.
The Architecture: Elastic GPU Capacity on Demand
At its core, this approach treats GPU selection as a workload concern, not an infrastructure concern. Here's how it works:
Karpenter monitors the Kubernetes cluster for pending pods that request specific GPU types. When a training job needs resources, Karpenter automatically provisions EC2 instances with the GPU architecture specified and the number of devices. Once training completes, those nodes can be set to automatically terminate. No manual scaling, no idle capacity eating your budget.
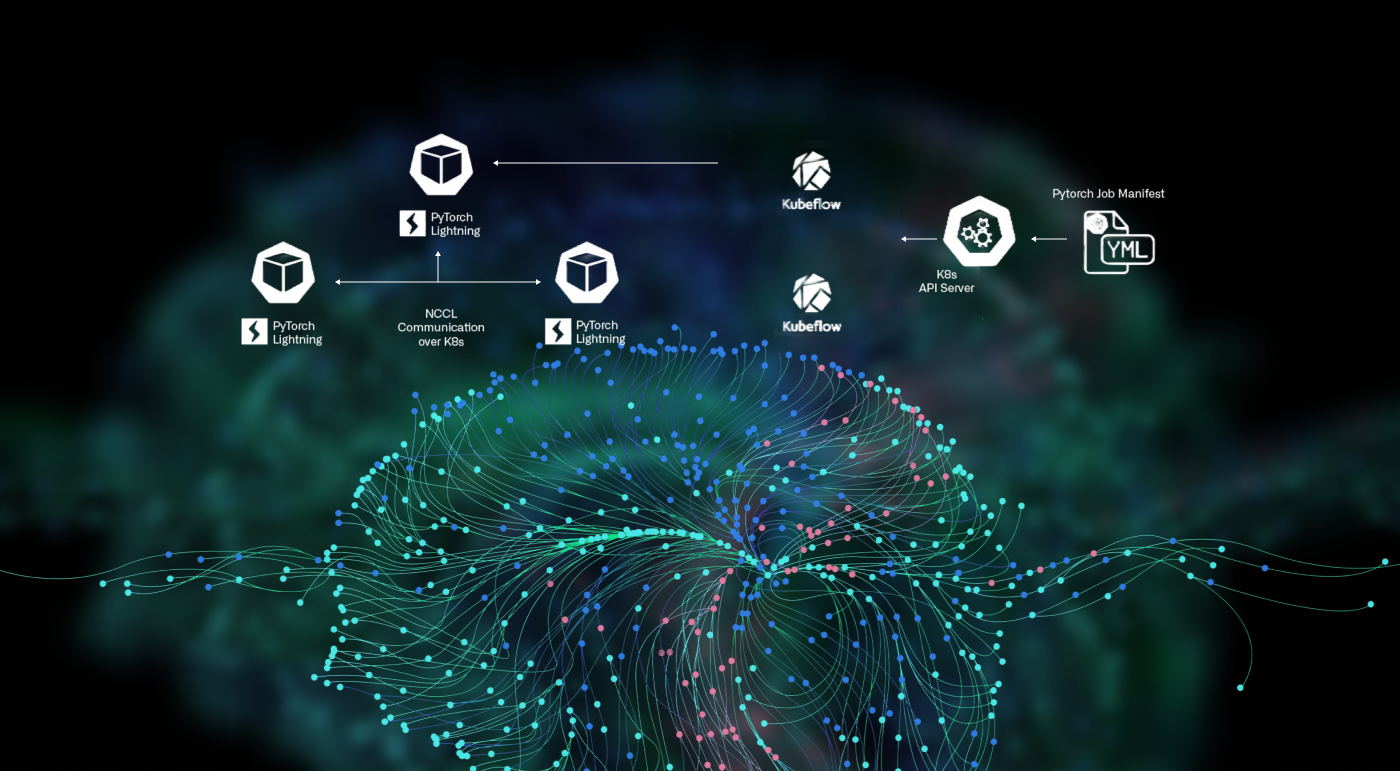
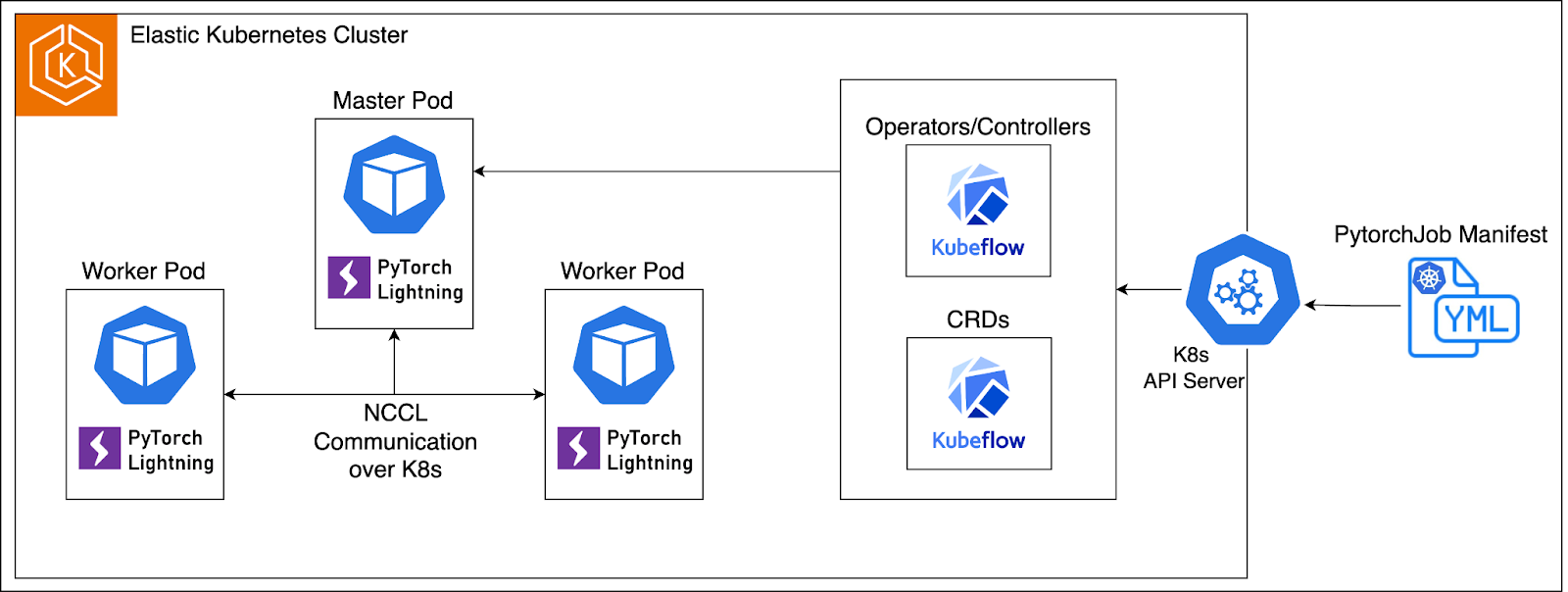
Kubeflow's training operators abstract away the complexity of distributed training. ML engineers write standard PyTorch or TensorFlow code, package it into a Docker image, and deploy it to the cluster with a simple Kubernetes manifest that specifies their requirements: number of nodes, GPUs per node, and instance type. The PyTorchJob or TFJob operator handles all the orchestration, spinning up master and worker pods, configuring distributed communication with the NVIDIA Collective Communication Library (NCCL), managing fault tolerance, and coordinating the training process.
The elegance of this approach is that switching from A100 to H100 GPUs requires changing only a single line in a YAML file. The infrastructure adapts automatically. This way, the architecture scales horizontally without artificial constraints. Need to run 8-node distributed training with 8 GPUs each? Define it in your manifest. Want to test the same run on a different chip architecture? Change the instance type in your manifest. Running multiple experiments in parallel? Karpenter provisions separate nodes simultaneously.This elegant abstraction is possible because of how the underlying components integrate with each other.
Now let's examine the architecture in detail to understand how these pieces work together to create a seamless training platform.
Building the Infrastructure: Components and Integration
Building a production-grade LLM training platform requires more than just compute. It also demands a cohesive system where storage, orchestration, experiment tracking, and deployment work together seamlessly.
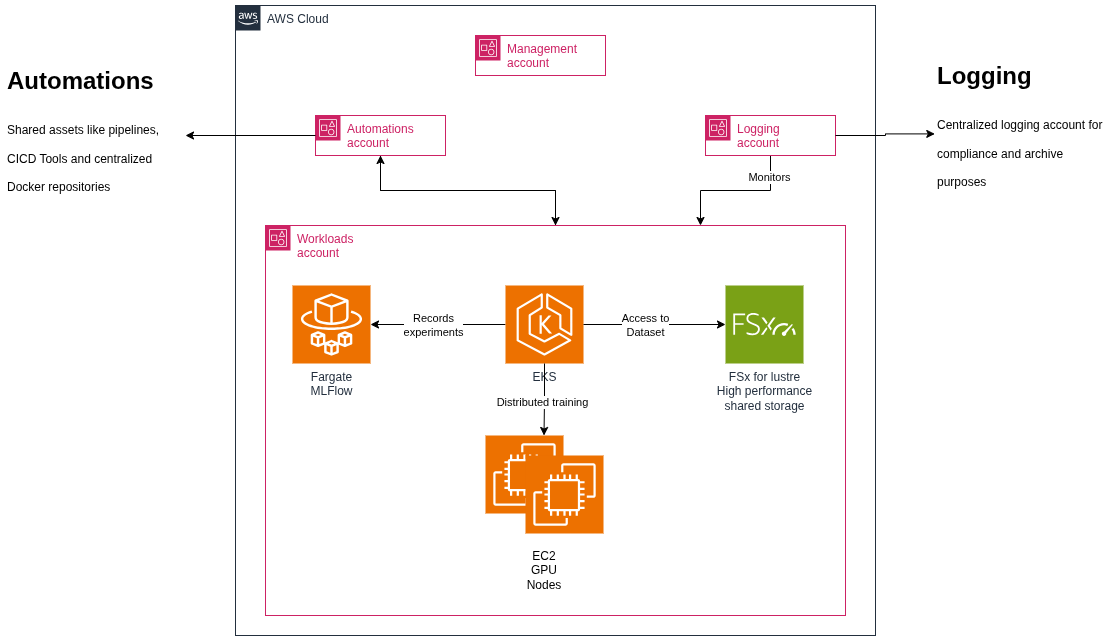
Our architecture follows AWS best practices with a multi-account strategy: separate accounts for automation (hosting shared services), workload environments (running actual training), and centralized logging. This provides security boundaries while maintaining centralized management through GitOps.
The diagram below illustrates how these components interact:
Amazon EKS: The Orchestration Foundation
Amazon EKS (Elastic Kubernetes Service) serves as our control plane, running version 1.32. We chose managed Kubernetes for several reasons that matter at scale: Native IAM integration eliminates credential management headaches, the managed control plane reduces operational overhead, and the ecosystem support for ML frameworks is unmatched.
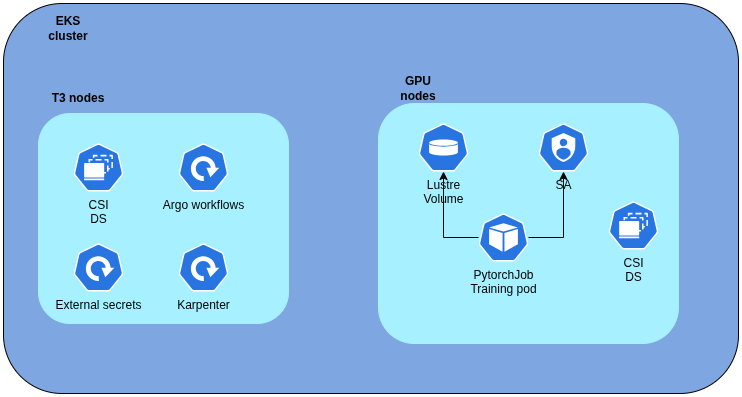
The cluster can run two distinct node groups. Static CPU nodes (for example t3a.large instances) handle cluster operations, workflow orchestration, and operational tools needed to run the desired setup; these stay running continuously. Dynamic GPU nodes, provisioned on-demand by Karpenter, provide elastic training capacity and exist only during active jobs.
Karpenter: Intelligence in GPU Provisioning
Karpenter makes this architecture truly elastic. Unlike traditional cluster autoscalers that work with predefined node groups, Karpenter provisions instances based on actual workload requirements.
We could define multiple node pools, each targeting different GPU architectures, like A100 pools, or H100 pools. When a training job lands in the queue requesting specific resources, Karpenter examines the requirements, selects the appropriate instance type, and launches it within minutes. The key insight: ML engineers declare what they need and Karpenter figures out how to provide it.
This approach eliminates the experimentation friction of traditional infrastructure. Testing different GPU architectures becomes a configuration change, not an infrastructure project.
Kubeflow Training Operators: Distributed Training Made Simple
Kubeflow's PyTorchJob and TensorFlow operators handle the complexity of multi-node distributed training. Engineers define their training topology—number of master and worker replicas, resources per pod, communication backends, and the operator manages the rest.
Behind the scenes, it coordinates PyTorch's distributed communication layer (NCCL for GPU training), manages pod lifecycles, handles failures gracefully, and ensures all nodes can discover and communicate with each other. The result: distributed training that works reliably without custom orchestration code.
Amazon FSx for Lustre: High-Performance Data Access
Training LLMs means reading terabytes of training data. Storage and I/O bottlenecks waste expensive GPU cycles, meaning that if your GPUs are waiting for data to complete batches, you're paying for idle compute. Maintaining GPU efficiency requires data pipelines that can feed batches as fast as the GPUs can process them. Any delay in data movement directly translates to delayed training steps and wasted resources. Considering that models are trained for thousands of steps, these small delays have a large compounding effect.
FSx for Lustre solves this problem with a high-performance parallel file system optimized for ML workloads. It delivers the throughput necessary to keep GPUs saturated, ensuring data movement never becomes the bottleneck in your training pipeline.
FSx volumes integrate directly with S3, and datasets stored in S3 automatically sync to the file system. Multiple training pods access the same data simultaneously with sub-millisecond latencies. The Kubernetes CSI driver mounts FSx volumes directly into training pods as persistent volumes, making data access transparent to training code.
MLflow on ECS Fargate: Centralized Experiment Tracking
Reproducibility matters in ML research. MLflow provides centralized tracking for experiments, metrics, parameters, and model artifacts. We run it on ECS Fargate (serverless containers) rather than in the training cluster. This keeps experiment tracking available even when all GPU nodes scale to zero.
MLflow's backend store runs on Aurora PostgreSQL for metadata, while S3 holds model artifacts and checkpoints. Training jobs authenticate to MLflow and log experiments programmatically. The setup is accessible via HTTPS through an Application Load Balancer with ACM certificates.
ArgoCD: GitOps Deployment
Every application and configuration deploys through ArgoCD using GitOps principles. ML engineers push changes to GitHub, such as workflow templates, Karpenter configurations, training job definitions. ArgoCD detects changes and syncs them automatically to the cluster,eliminating configuration drift, providing a complete audit trail, and making rollbacks trivial.
The ML Engineer Experience
With this infrastructure in place, the workflow for training an LLM becomes remarkably straightforward. What previously required infrastructure tickets, capacity planning meetings, and days of setup now happens in minutes.
Here's the complete flow:
- Prepare your training code and data. Push datasets to S3, which automatically syncs to the FSx file system. Your training script remains standard PyTorch or TensorFlow, no special modifications required for distributed training. Consider model distribution strategies such as DDP, FSDP, and ZeRO for scaling up the training steps.
- Define the training job. Create a Kubeflow PyTorchJob manifest that declares your requirements. Specify the number of nodes, GPUs per node, the instance type, memory and CPU resources, and mount the FSx volume for data access. This is a single YAML file, typically under 100 lines.
- Submit and run. Apply the manifest directly to the cluster with kubectl apply -f training-job.yaml. Karpenter provisions the exact GPU nodes you specified. The training begins, with Kubeflow managing all distributed coordination.
- Track and iterate. Your training script includes MLflow logging calls to track metrics, parameters, and artifacts. Monitor training progress, compare experiments, and analyze results, all from the MLflow dashboard. When training completes, the GPU nodes terminate automatically.
Infrastructure as Code: Deployment and Management
Ideally, the entire platform should be defined and deployed using Infrastructure as Code with Terraform and Terragrunt. This configuration ensures consistency across environments, makes the stack fully reproducible, and enables version-controlled, auditable infrastructure changes.
Terragrunt orchestrates dependencies between components. The infrastructure deploys in two phases: first the core AWS resources (VPC, EKS, Aurora, FSx, S3), then the Kubernetes configurations and add-ons (Karpenter, ArgoCD, Argo Workflows, and ML namespaces).
This repeatability matters for disaster recovery, multi-region deployments, and maintaining separate development and production environments with identical configurations.
Cost and Observability Considerations
LLM training is expensive, but this architecture includes several controls to manage costs effectively. Karpenter's autoscaling means GPU nodes only exist during active training, so you’re not paying for idle capacity. Node pools can be configured to use spot instances where appropriate, offering significant savings for fault-tolerant workloads. Kubernetes resource quotas prevent runaway experiments from consuming unlimited resources. FSx backups use configurable retention policies with S3 lifecycle rules. And Fargate's serverless pricing for MLflow means you pay only for actual runtime, not reserved capacity.
Observability and Optimization
MLflow provides more than just experiment tracking; it's also a powerful tool for infrastructure optimization. By logging GPU utilization metrics, memory consumption, and throughput statistics alongside model metrics, teams gain visibility into how efficiently they're using resources.
This observability reveals critical insights: Now you can identify bottlenecks in data loading or preprocessing that keep GPUs idle, evaluate Model FLOPs Utilization (MFU) to understand how close you are to theoretical peak performance, detect memory leaks in training code that demand excessive CPU capacity, and spot inefficient batch sizes or parallelization strategies that waste compute.
These insights translate directly to cost savings. A training run operating at 30% MFU wastes 70% of your GPU spend; fixing the bottleneck achieves the same results at a fraction of the cost. CloudWatch complements this improvement by collecting logs and metrics from all infrastructure components, enabling proactive monitoring and rapid troubleshooting when issues occur.
Abstracting Infrastructure, Unlocking Models
Building infrastructure for LLM training requires balancing flexibility, performance, and cost. The challenge isn't just provisioning GPUs; it's creating a platform where ML engineers can focus on model development rather than infrastructure management.
By treating GPU selection as a workload concern rather than an infrastructure concern, we've eliminated the traditional friction of hardware experimentation. Testing across different GPU architectures becomes as simple as editing a YAML file. The infrastructure adapts automatically, scales without artificial limits, and cleans up after itself.
The key insight: The right abstractions make hard problems simple. Kubernetes provides the orchestration foundation. Karpenter brings intelligent, workload-driven provisioning. Kubeflow handles distributed training complexity. FSx ensures data never becomes a bottleneck. GitOps keeps everything version-controlled and auditable.
For organizations building specialized models, this architecture provides the foundation for rapid experimentation and iteration. The infrastructure scales with your ambitions, provisions exactly what you need when you need it, and stays out of your way the rest of the time.All infrastructure is version-controlled, reproducible, and deployed through automation, enabling the rapid iteration that modern LLM research demands.




