
Listen to this article:
As AI scales to handle increasingly complex tasks, we face a dilemma: How can we efficiently verify its outputs for accuracy and veracity? More importantly, can an unverified AI ever be truly useful—or safe—at all?
Large Language Models (LLMs) have emerged as powerful tools by democratizing access to sophisticated natural language processing capabilities. But LLMs suffer from a fundamental flaw: They’re trained on the majority of digitized human expression, which is inherently imperfect human-generated data. This problem is at the heart of our work at Loka, where we aspire to build systems that can go beyond their training data.
Evaluating the accuracy of LLMs isn’t just a technical challenge—it’s also an existential one. If we want to build trustworthy AIs, we must find ways to assess their outputs effectively, objectively and at scale. Relying solely on human evaluation and verification isn't feasible because it creates an efficiency bottleneck while introducing the very imperfections, inconsistencies and human biases we're trying to overcome.
Traditional Natural Language Processing (NLP) evaluation metrics like BLEU and ROUGE measure how closely a machine-generated response matches a human one by comparing overlaps in words and phrases. BLEU (Bilingual Evaluation Understudy) checks for exact matches in short word sequences, while ROUGE (Recall-Oriented Understudy for Gisting Evaluation) focuses on how much of the human-written reference is captured in the model’s output. They’re useful but don’t fully capture the fluency of expression, logical coherence, creative insight and fairness that we value in a compelling (i.e. helpful and properly contextualized) response.
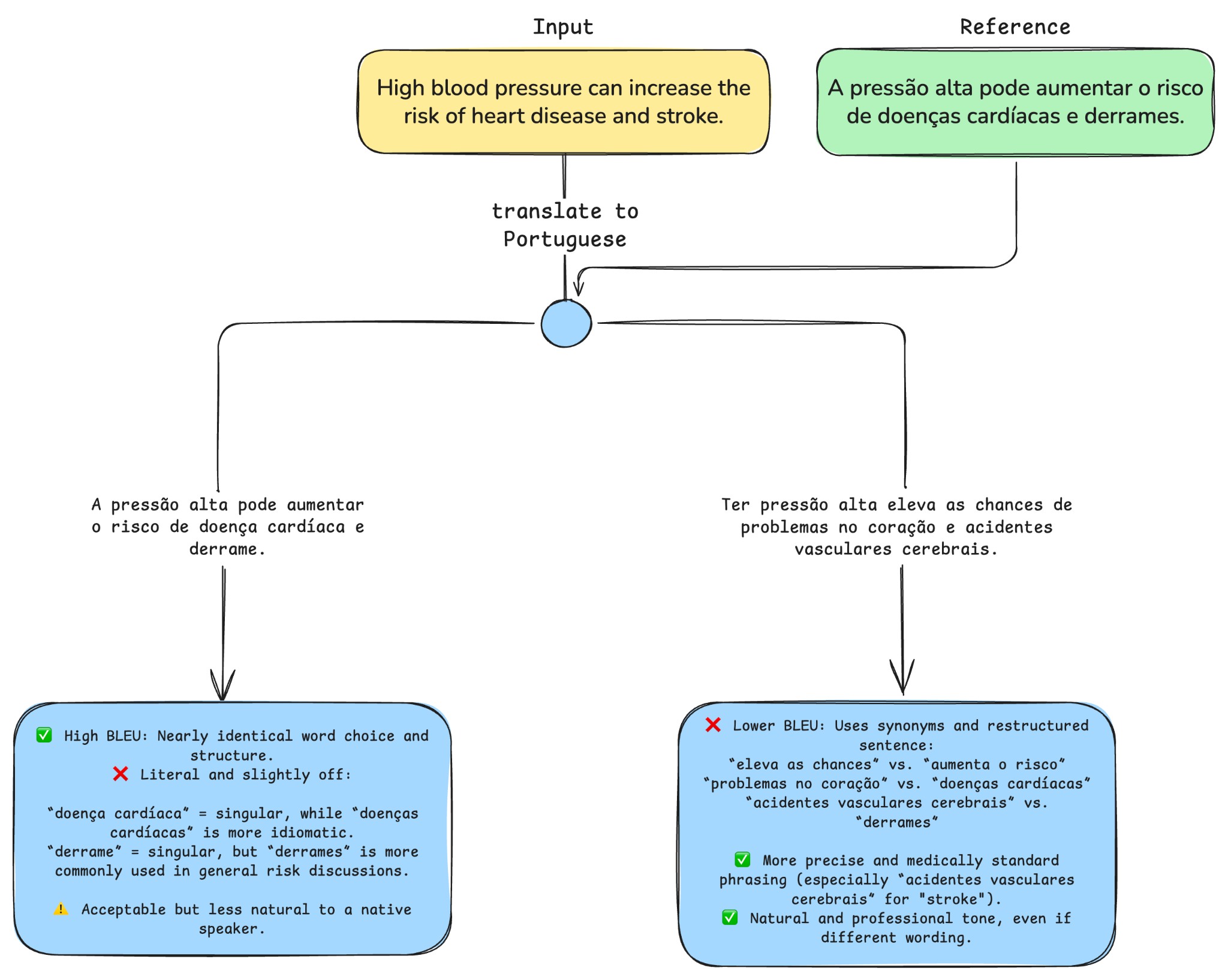
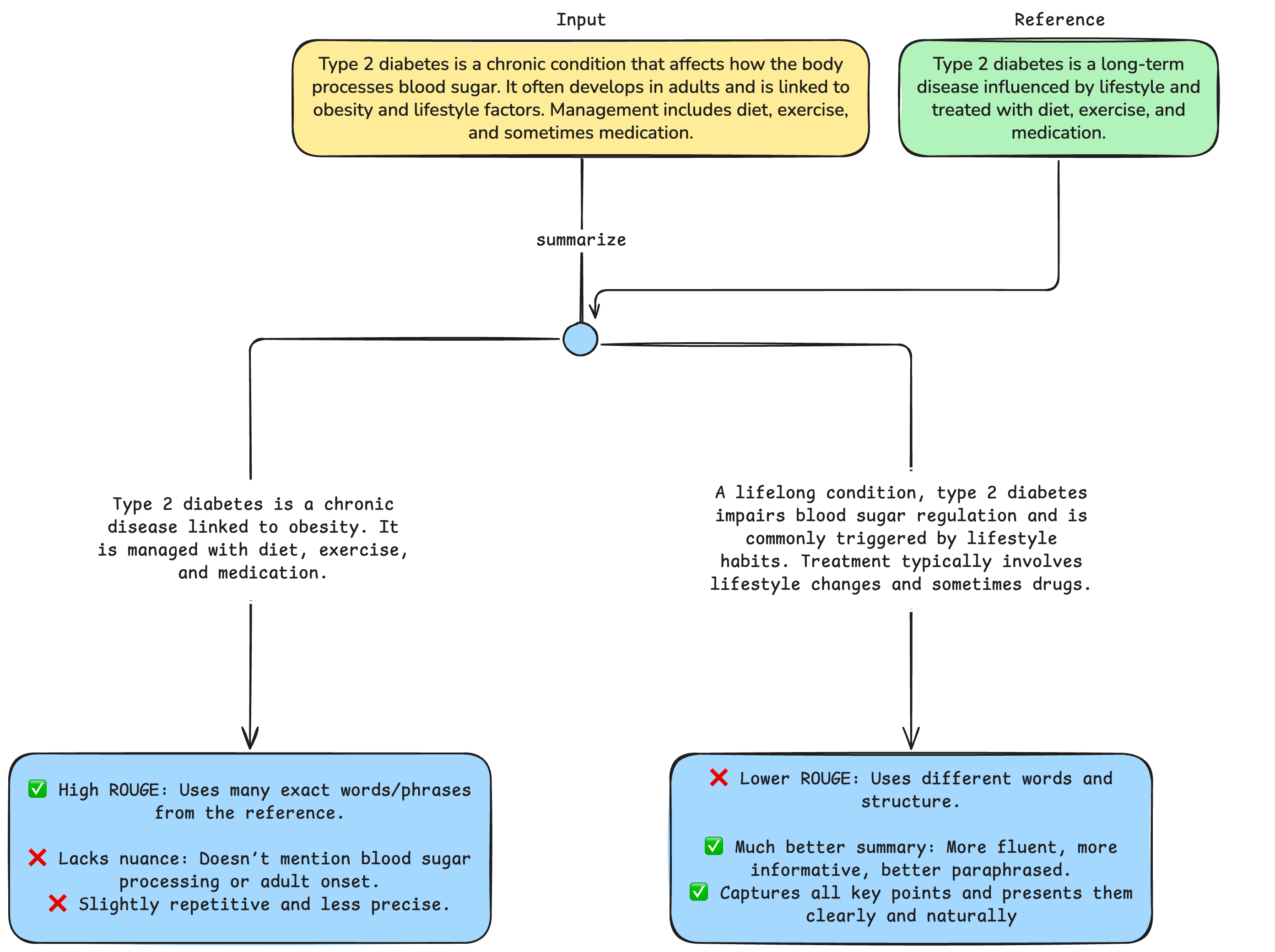
Enter LLM-as-a-Judge, the technique of using an LLM to evaluate the output of another model—or even itself—based on defined, context-based criteria. LLM-as-a-Judge provides transparent, interpretable assessments, making model evaluation clearer and more scalable. Beyond a technical fix, this innovation moves us closer to a system that understands quality the way humans do, only at massive scale.
Speaking of quality, by embracing the challenge of AI evaluation, we not only refine the technology but also grapple with the definition of quality itself. Evaluating for quality isn’t an afterthought—it’s a requirement for any AI project. Without it, we risk deploying systems that might produce unreliable outputs, exhibit unmeasured biases or fail to meet performance benchmarks necessary for scalability and iterative improvement.
With quality outputs in mind, Loka’s ML team recently built an automated evaluation pipeline for one of our projects. In the process we refined our internal approaches, methodologies and implementation strategies while managing key trade-offs, limitations and unexpected strengths. Through this process we built a system that delivers consistent, explainable and scalable evaluations, ultimately improving how we assess and iterate on model performance.
Crafting the "Perfect" LLM Judge
There's no one-size-fits-all solution for designing an LLM-as-a-Judge pipeline. Each approach must be tailored to the specific evaluation needs of the project. What exactly is the LLM evaluating? Which criteria matter most for the use case? What defines success for this evaluation? What quality standards should guide the assessment? We had to answer these questions to develop an automated evaluation solution for our client.
We began by examining our fundamental assumptions about quality and truth. What were we really trying to measure, and why did it matter?
Our pursuit of an effective evaluator echoes a broader human pattern: We chase perfection not because it's attainable, but because it drives innovation. In other words, we don’t expect perfection but rather improvement. Each prompt iteration, scoring tweak, and pipeline revision brings us closer not to flawlessness but to insight.
Our journey became one of continuous discovery—building, testing, visualizing, analyzing and refining in an endless cycle of improvement. We recognized that perfection will always remain just beyond reach, both for our LLMs and for ourselves. Yet remarkably, our progress accelerated until we reached a plateau that seemed to mark a natural boundary of current capabilities.
Due Diligence
“If I have seen further, it is by standing on the shoulders of giants.” —Isaac Newton
.png)
A critical early step in developing any robust ML solution is reviewing the existing literature to understand the current state of research, methodologies and benchmarks. By exploring the existing research, we connect with the other minds working toward similar goals. This collaborative spirit allows us to build upon the foundations laid by others while potentially advancing knowledge incrementally toward that ever-elusive perfection we’re reaching for.
Our research led us to an evaluation framework (Li et al. 2024, Gu et al. 2025) with four key inputs:
- Evaluation type: The methodology we'd use to assess content
- Assessment criteria: The specific dimensions of quality we'd measure
- The item being evaluated: The content requiring assessment
- Reference materials: Optional supplementary information for context
From these inputs, our framework generates three distinct outputs:
- Quantitative results: Numerical scores reflecting performance
- Qualitative explanation: Detailed reasoning behind each score
- Constructive feedback: Actionable recommendations for improvement
With this structure established, the next step was experimenting to refine the approach and address key gaps in evaluation and methodology.
Choosing the Right Lens
.png)
Regarding the evaluation type, three primary methodologies exist:
- Pointwise Evaluation: This method assesses individual outputs against defined criteria, generating absolute scores (think "rate this text from 0-5" or "classify as true or false" assessments). This evaluation type struggles with capturing subtle differences between outputs or maintaining score consistency across different judge models, but it shines in scalability and explainability.
- Pairwise Evaluation: Here we directly compare two candidates to determine which performs better according to specified criteria. Research consistently shows stronger alignment between LLM and human evaluations in pairwise evaluations versus absolute scoring methods, which are usually used in pointwise evaluation.
- Listwise Evaluation: This approach takes a holistic view, evaluating multiple candidates simultaneously and ranking them based on specified criteria. It's particularly effective for tasks requiring relational analysis, as this method accounts for relationships between candidates and enables a deeper assessment of preferences, though it’s less commonly implemented than the other two approaches.
Each use case demands its own approach. For example, when evaluating document retrieval in search engines, listwise evaluation is typically preferable, because relevance is inherently comparative; ranking multiple results captures not just individual quality, but their relative usefulness to the query. In our use case, we needed an absolute measure of quality for every entry. This made pointwise evaluation the natural choice for us.
The Quest for Meaningful Judgment
Designing an LLM-as-a-Judge system isn’t just about choosing a framework, it’s about defining what makes a good evaluation in the first place. If an LLM judge is to be trusted, its judgment must be meaningful, repeatable, and more importantly, aligned with human intuition. But what does “good” even mean in this context? What separates a rigorous evaluation from a shallow one?
.png)
The core metric in LLM evaluation literature is helpfulness—typically defined as how effectively a model’s response addresses a user’s query by being accurate, relevant, actionable, and clearly communicated. On the surface, this seems straightforward. But in practice, helpfulness is a deceptively complex construct, composed of interdependent qualities like factual accuracy, contextual relevance, logical coherence, and even creativity.
Some evaluation criteria, like accuracy, translate easily into metrics. Others, such as fluency or logical consistency, required us to think deeply about how humans recognize quality in communication, leading to several iterations as we refined our approach.
Traditional reference-based evaluations work well when there's a clear right answer. However, real-world problems rarely offer such clarity and objectivity. Our reference-free evaluation approach acknowledges this disparity, judging outputs on intrinsic qualities rather than adherence to an imperfect gold standard. This measurement mirrors how we naturally evaluate new ideas, drawing on prior references when possible while critically assessing their inherent value.
This approach introduced a fundamental challenge: How does an AI judge what it doesn't inherently know? Unlike human experts who, although imperfect, draw on lived experience and specialized knowledge, LLMs lack true domain expertise. Thoughtful prompt engineering became the bridge between AI capabilities and human-like judgment.
For instance, when building the user prompt, we guided it with four sub-dimensions—accuracy, completeness, structure, and tone—rather than relying on a single metric. We also defined each of these dimensions clearly within the prompt, ensuring the model understood what to prioritize in its judgment and why. Where an unprompted model might default to simplistic or inconsistent scoring, this approach encourages it to weigh multiple considerations at once, balancing them in a way that more closely mirrors human thinking.
From Algorithm to Insight
We made a strategic decision early in the process: Our evaluation system would be powered by a single-LLM approach. After multiple iterative rounds of testing, we specifically selected Claude 3.7 Sonnet. This model would handle the entire evaluation pipeline: assessing criteria, providing reasoning, and generating actionable feedback. A single-model approach streamlined our pipeline and enhanced scalability, but it meant the quality of evaluation depended entirely on this model's capabilities and how effectively we designed our prompts.
.png)
So we iterated. Again and again. To guide the model toward more reliable assessments, we refined our prompts with four different strategies:
- In-context learning provided explanations or explicitly curated examples within the prompt to shape the LLM's behavior.
- Step-by-step reasoning in non-reasoning models improves the quality and reliability of LLM-based evaluations by encouraging more structured thinking, including
- Chain-of-thought prompting to encourage methodical, structured decision-making.
- "Explanation-rating" methodologies that enhanced reliability by requiring explanations before ratings.
- Decomposing complex evaluation standards into specific, discrete criteria, allowing the LLM to assess each aspect independently.
- Definition augmentation injected domain-specific knowledge directly into the prompt to compensate for the model's knowledge gaps.
- Multi-turn optimization framed the evaluation as an iterative dialogue, allowing the model to refine its judgments dynamically.
This process—tweaking prompts, testing outputs, analyzing results and refining—became the heartbeat of our evaluator's development. Each refinement pushed us toward more consistent and trustworthy assessments while we remained mindful of the constraints inherent to a single-model approach.
For other use cases, some teams might implement multi-LLM evaluation systems where models function as collaborative or competitive judges. This approach can improve reliability but introduce increased complexity, computational expense and potential inconsistencies between models. We opted instead for a streamlined system that acknowledges an essential truth: The most powerful approach combines machine precision with human insight. While the LLM carried out the evaluations, it was human supervision that shaped what it prioritised and valued. Our role wasn’t simply to design better prompts; it was to interpret behavior, notice inconsistencies and ask better questions. Every successful iteration reflected our ability to read between the lines of the model’s outputs and refine our approach accordingly.
Ironically, the more we tried to automate judgment, the more we encountered the limits of the definition of quality itself. Behind each “objective” score lie deeply human decisions like how we define quality, what we value in communication, and where we draw the line between acceptable and exceptional. These moments revealed a deeper truth: Our efforts to make AI judgment more rigorous inevitably brought us face to face with the subjectivity and imperfection of our own.
In Part 2, we’ll explore this tension more fully, investigating how the very human instincts that helped us build better evaluators may also be the source of persistent bias, inconsistency and blind spots. Building machines that can effectively judge requires first understanding how flawed our own judgments can be—and what we can do about it.



